18 Dec 2024
Introducing the SWT-Bench Leaderboard!
SWT-Bench: Benchmarking CodeAgents’ Test Generation Capabilities
As the complexity of modern software systems grows, so does the challenge of ensuring their reliability. To this end, rigorous testing plays a critical role in maintaining high software quality. However, while the rise of Large Language Models (LLMs) has catalyzed advancements in code generation, their potential in test automation remains underexplored. Enter SWT-Bench, a novel benchmark for test generation based on real-world GitHub issues, developed in collaboration with ETH Zurich. With the release of a public leaderboard at swtbench.com, we aim to spark a similar push from the research community on test generation as SWE-Bench caused for code generation.

What is SWT-Bench?
SWT-Bench is a test generation benchmark based on real-world GitHub issues. The objective is to generate a test reproducing the described issue given the full codebase. We determine whether a test reproduces an issue by checking whether it fails on the original codebase but passes after a human-written ground truth fix, taken from a corresponding pull request (PR), has been applied. We call this the success rate \mathcal{S} Additionally, we measure the coverage \Delta \mathcal{C} of the lines modified in this ground truth bug fix to further assess the test quality.
How did we create SWT-Bench?
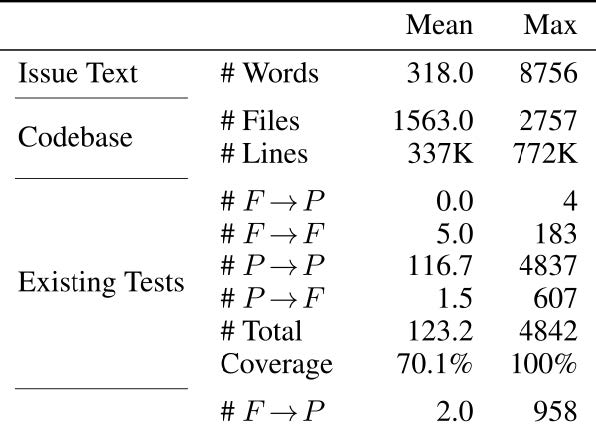
Starting with over 90,000 PRs from 12 popular GitHub repositories, we applied rigorous filtering to obtain 1,900 diverse and high-quality instances. SWT-Bench thus reflects the complexity of modern software ecosystems, challenging AI systems to navigate large codebases (up to 700k lines), interpret nuanced issue descriptions (320 words average), and integrate tests into diverse existing test suites and frameworks (from pytest to tox to custom frameworks).
First Results
Performance of Code Agents
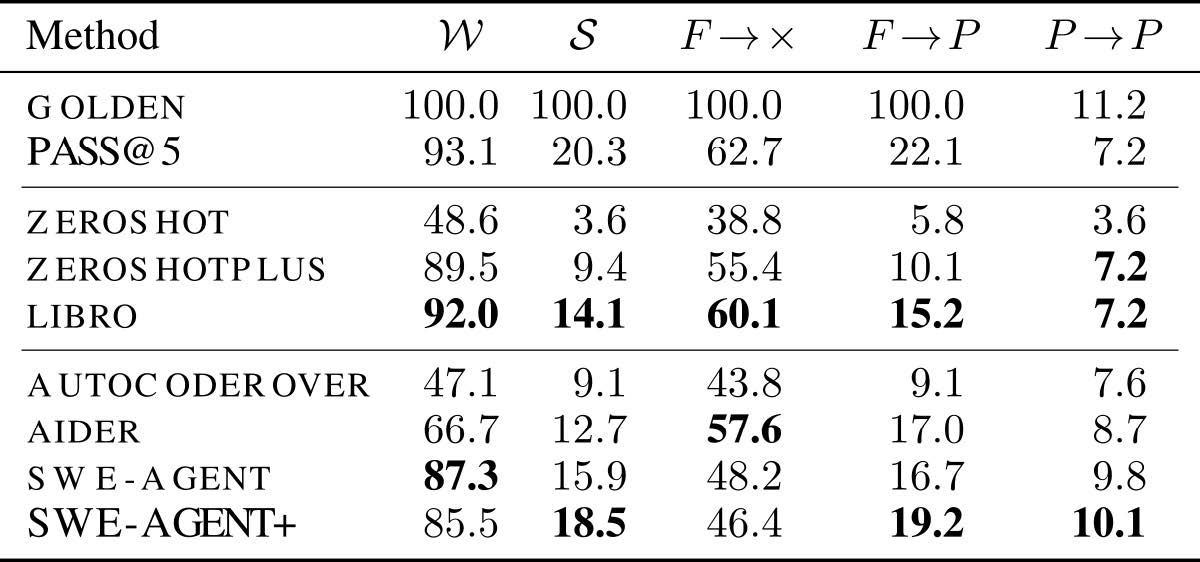
We found that Code Agents, originally designed for program repair (e.g. SWE-Agent), perform well on test-generation tasks, even outperforming dedicated test-generation methods (LIBRO). However, even minimal modifications like explicitly instructing the agent to execute the generated tests (SWE-Agent+) significantly improve performance further. This highlights the potential of dedicated Code Agents for test generation.
A new Patch Format for Test Generation
Based on the insight that test generation is typically solved by adding a new (test) function or class, we propose a novel patch format tailored for fault tolerance and simplicity. This format alone, allows vanilla LLMs to generate executable tests in twice as many cases (ZeroShot vs ZeroShotPlus) leading to almost 3 times as many solved instances.

Utility of generated tests:
Automatically generating high-quality tests not only allows developers to focus on (test-driven) development generating real business value but can also boost the performance of code generation agents. In particular, the generated tests can guide them along the whole generation process from informing context localization to bug fix validation. Early results show that simply using generated tests to filter proposed bug-fixes can more than double the achieved precision.
Correlation of Test and Fix Generation
While we observe that Code Agents who perform well on code generation also perform well on test generation, we interestingly doe not see such a correlation for individual issues. That is an issue that is easy to fix is not necessarily easy to test and vice versa. Indeed, we see no statistically significant correlation between the hardness/resolution rate of these tasks, highlighting the unique challenges of test generation.
Implications for the Future of Software Maintenance
SWT-Bench demonstrates the capability of LLMs to interpret and formalize the intent of natural language issue descriptions into tests. This has the potential to in the long run significantly improve software quality by making thorough testing attainable without significant manual efforts. In a next step, this can even enable self-healing systems by automatically detecting, reproducing, and resolving issues in real-time, as they appear, minimizing downtime and increasing reliability.
We at LogicStar AI believe that reliable automated testing is the key to unlocking the real potential of Code Agents and will be essential to push the frontier in automated application maintenance. Therefore, we are extra excited to see the great interest of the community in SWT-Bench and hope that our public leaderboard can make it even more accessible.
For more details, check out our NeurIPS paper (https://arxiv.org/pdf/2406.12952) or our open-source code (https://github.com/logic-star-ai/swt-bench.