March 9, 2026
-
time
min read
Beyond SWE-bench: The Hardest Problem in AI Software Engineering Isn’t Writing Code
Over the past two years, coding agents have made astonishing progress. Modern models can write entire functions, generate patches, and even implement large features. Benchmarks like SWE-bench have become a standard way to evaluate these capabilities. But something important is changing. Recently, OpenAI explained why they are moving away from evaluating models using SWE-bench Verified as the primary benchmark for AI software engineering systems. Their reasoning reflects a deeper shift in how the industry is thinking about AI-driven development. The problem is no longer just writing code. The real problem is deciding what code should change in the first place.
SWE-bench has played an important role in advancing AI coding systems. The benchmark asks models to resolve real GitHub issues by producing patches that pass the project's test suite. In simplified form the evaluation looks like this: the agent receives a repository, reads an issue description, generates a patch, and the patch must pass the tests. This measures an important capability: can an AI system implement a fix once the problem is clearly defined? But this assumption hides an important simplification. In real software engineering the hardest part is rarely writing the patch. It is figuring out what the correct change should be.
Benchmarks assume a well-formed problem statement. Real software development rarely looks like that. Instead engineers see signals coming from many different systems such as logs and observability platforms, incident alerts, bug trackers, security scanners, static analysis findings, failing CI tests, and customer reports. Each signal may represent only a symptom of a deeper issue. Before any fix can happen engineers must answer a much harder question: which issue actually matters right now? Answering this requires architectural understanding, system knowledge, and engineering judgment.
Recent research from ETH Zürich and LogicStar explored this challenge with a benchmark called CodeTaste. CodeTaste evaluates whether coding agents perform large-scale refactorings in ways that align with human engineers. Unlike many benchmarks CodeTaste focuses on architectural changes across large codebases. The benchmark contains one hundred real refactoring tasks extracted from open-source repositories across six programming languages and each task touches roughly ninety-one files on average. Instead of measuring only correctness CodeTaste measures alignment, which rewards changes that match the structure chosen by the original human refactoring while preserving functional correctness. In other words it evaluates whether the automated change preserves the architectural intent behind the human change. The results are revealing. When given a detailed refactoring blueprint, frontier models achieve alignment scores of up to 70%. When given only a high-level goal, alignment collapses to below 8%. Even when agents first propose a plan and then implement it alignment improves only to around 14%.

These results highlight an important limitation. Coding agents today are extremely capable instruction followers. When the plan exists they can execute it, but they still struggle with engineering judgment. Experienced engineers do not just write code. They decide what problem actually needs to be solved, how large the change should be, which architectural trade-offs are acceptable, and how to maintain long-term system integrity. In other words the real challenge in software engineering is not writing the patch. It is identifying the right problem to solve and making the architectural trade-offs required to address it sustainably.
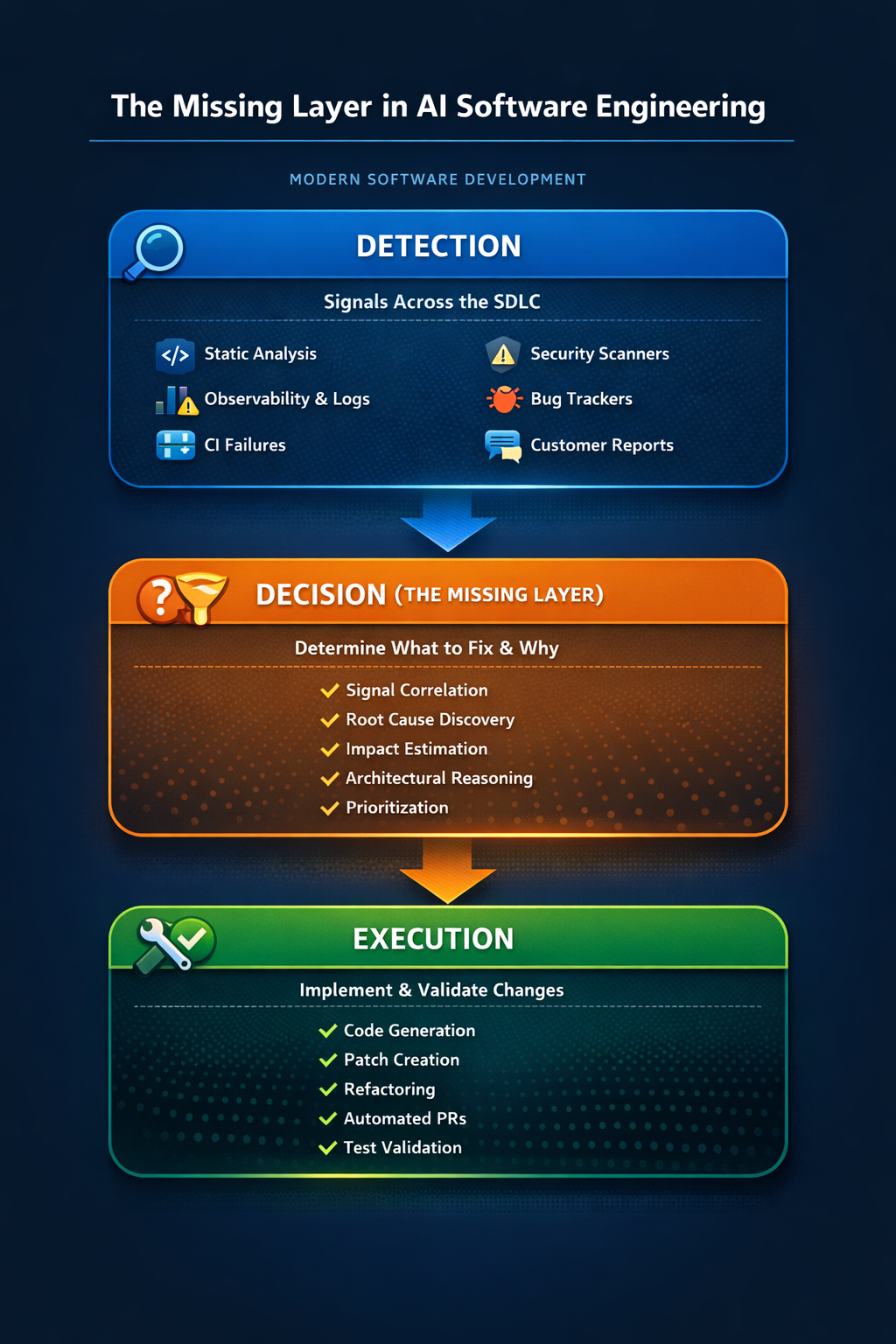
The industry has invested enormous effort in improving code generation. But the future of AI in the SDLC likely depends on solving a different problem. Between detection and fixing lies a critical layer: decision making. This layer determines which signals represent real problems, which issues have the highest impact, and what changes should actually be made. Without this layer AI systems remain tools that help engineers write code. With it they begin to approach autonomous software engineering systems. A realistic AI engineering system therefore needs three capabilities working together. Detection gathers signals from across the development lifecycle including static analysis, observability systems, CI pipelines, security scanners, and bug trackers. Decision determines what should be fixed and why through signal correlation, root cause discovery, impact estimation, architectural reasoning, and prioritization. Execution generates and validates the actual code changes through patch generation, refactoring, automated pull requests, and testing. Most current AI tools focus primarily on the execution layer, but without the decision layer automation risks optimizing the wrong problems.
The vision of autonomous software development is becoming increasingly realistic. Coding agents will continue to improve rapidly, but the next breakthrough may not come from models that write code faster. It will come from systems that understand what changes should happen and why. Future systems must preserve architectural intent when engineers guide them and will need to develop architectural foresight as automation increases. Benchmarks like SWE-bench helped the industry measure the first generation of AI coding capabilities, while research like CodeTaste begins to measure the next generation: the ability to align automated changes with human engineering judgment.
CodeTaste was developed as part of an ETH Zürich MSc thesis by Alex Thillen, supervised by Niels Mündler, Martin Vechev, and Veselin Raychev.

LogicStar shows the bugs impacting customers and revenue, ranked and ready to act on.
No workflow changes. Results in ~1 hour.



















.png)